
30 September 2020

Song Yu
Hitachi (China) Research & Development Corporation
This blog is not about AI/Analytics per se but a new system architecture we developed to prepare complex real-world data for machine learning in the future. Several years ago, hospital data in China was distributed in different medical systems. In particular, hospitals hold various medical records of patients in large volume with diverse formats [1], including not only structured data, but also unstructured data, such as dictation, handwriting, photographs, images, etc. [2]. Diverse data formats require flexible data storage and access, whereas large volume of data asks for high scalability and availability. Although some Chinese companies have developed data integration systems, most of them are still not able to integrate complicated hospital data, and in particular, are not able to integrate structured data and unstructured data. We decided to address this challenge, and developed this system architecture. In this blog article, I outline the system design, distributed crawler architecture and distributed strategy that we employed in an integrated retrieval system to create a system that meets the above needs and realizes the collection, storage, retrieval and visual display of such massive and diverse data.
In existing hospitals, available data includes electronic medical records in HIS (Hospital Information System), inspection reports in LIS (Laboratory Information Management System) system and DICOM (Digital Imaging and Communications in Medicine) files in PACS (Picture Archiving and Communication Systems) system [3].

Figure 1: Module design of integrated retrieval system
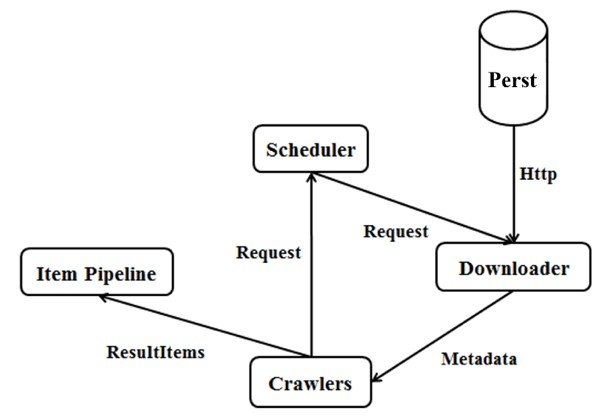
Figure 2: The difference between SQL and NoSQL
The system adopts NoSQL instead of a traditional SQL relational database to allow for flexible data storage and access [4]. In addition, the index database is based on Solr, which is a high-performance full-text search server that can be easily scaled up by adding storage devices and search engine servers [5], which ensures high scalability and availability.
Furthermore, we introduced a new distributed crawler architecture as shown in Figure 3 to the Index Construction Module to crawl large-capacity data quickly and in real time. In this architecture:
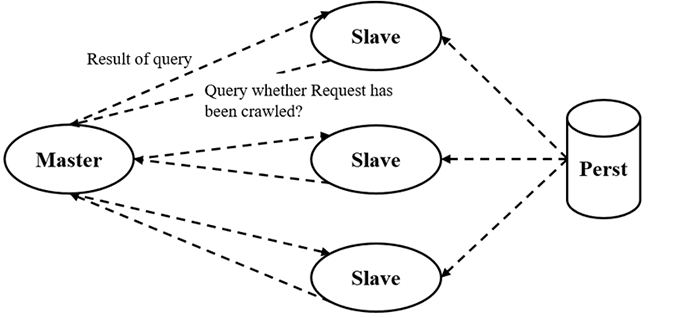
Figure 3: Distributed crawler architecture
The cluster crawler in Figure 3 above contains multiple crawler devices and follows a distributed strategy as shown in Figure 4 below, where
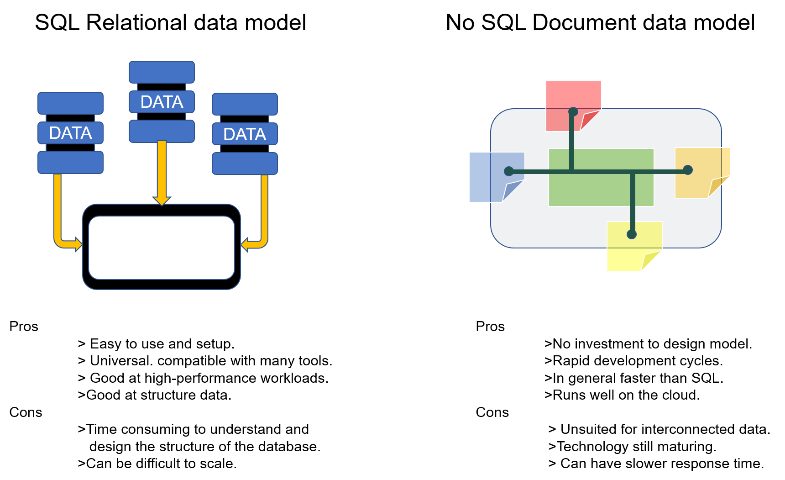
Figure 4: Distributed crawler strategy
After the system starts, crawlers occasionally run as the Scheduler keeps a record of the creation time of the last-visited metadata files and arranges crawlers to only crawl data that have not been crawled before. The distributed structure of the crawler also makes it easy to scale-up.
In this blog, I outlined a new system architecture for integrated retrieval which enables easy and fast access to massive medical data as well as providing high scalability and availability of service by maintaining proper loose coupling among modules and adopting NoSQL and distributed strategy. In terms of application, we did the trials in some hospitals, having extracted HIS, LIS and DICOM data and completed the integration. Of course, appropriate modifications to this system architecture can also be applied to other scenarios. And to find out more about our proposed system, please refer to my paper, “Integrated Retrieval System Based on Medical Big Data” which is included in the Proceedings of the 3rd International Conference on Vision, Image and Signal Processing (ICVISP2009),
I would like to thank my team members for sharing their pearls of wisdom with me.