
19 October 2020

Yang Zhang
Hitachi (China) Research & Development Corporation

Lu Geng
Hitachi (China) Research & Development Corporation
Deep neural networks (DNNs) are state-of-the-art solutions for many machine learning applications, and have been widely used on mobile devices. When we run DNN (deep neural networks) on resource constrained mobile devices, we offload computation from mobile devices to edge servers. However, offloading itself can present a major challenge as data transmission using band-width limited wireless links between mobile devices and edge servers is time consuming. Previous research to resolve this issue has focused on the effect of the selection of partition position. The two parts of DNN are stored on the mobile device and edge server and executed, respectively (Figure 1). There is the possibility however that when the output data size of a DNN layer is larger than that of the raw data, this will cause high transmission latency. From our studies, which I have summarized below, we are recommending a 2-step pruning framework for DNN partition between mobile devices and edge servers for efficiency and flexibility.
Pruning is a means of reducing the size of neural networks. In our recommended framework, the DNN model is pruned in the training phase where unimportant convolutional filters are removed. The recommended framework can greatly reduce either the transmission workload or the computation workload. Pruned models are automatically selected to satisfy latency and accuracy requirements. Experiments showed the effect of the framework.
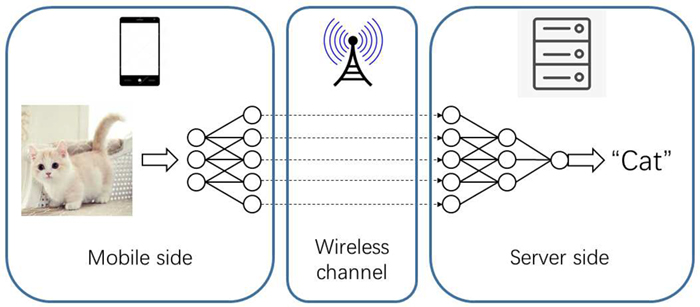
Figure 1: An illustration of device-edge cooperative inference.
The recommended framework contains three stages: offline training and pruning stage, online selection stage and deployment stage. In the 1st stage, two pruning steps are carried out, where pruning takes place in each entire layer in the whole network and restricts the action ranges for each layer. In the 2nd stage, a partition point is selected according to the restriction of latency-accuracy constraint. In the 3rd stage the computation is divided for mobile devices and edge servers.
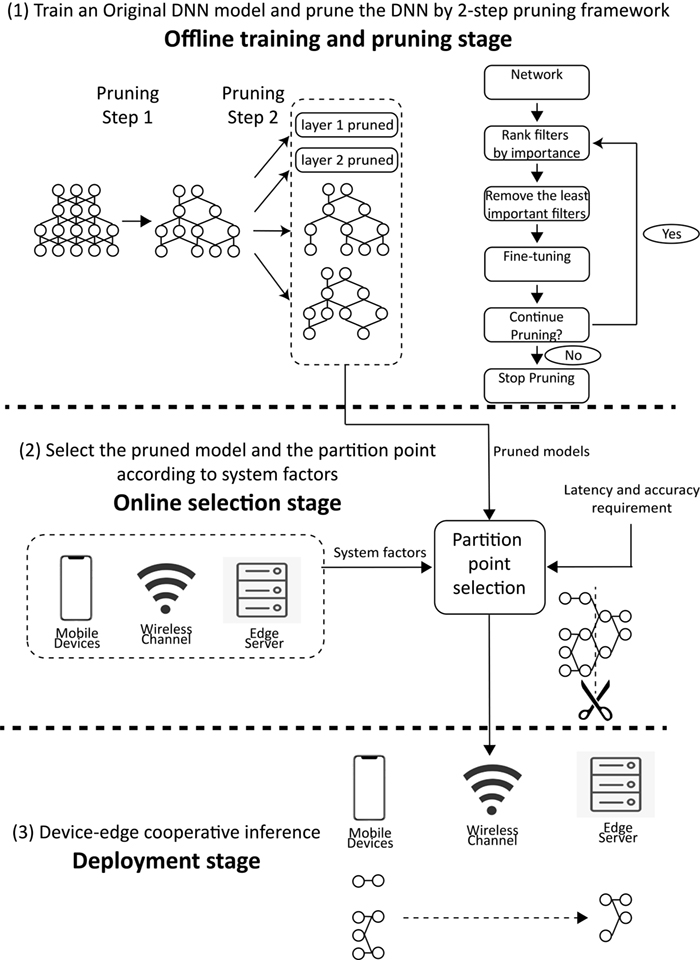
Figure 2: Proposed 2-step pruning framework.
The pruning experiment is carried out on VGG.[14] Figure 3 shows the transmission workload and cumulative computation time at each layer for the original VGG model, VGG model after pruning step 1 and VGG model after pruning step 2, respectively. A 25.6× reduction in transmission workload and a 6.01× acceleration in computation compared to the original model are achieved.
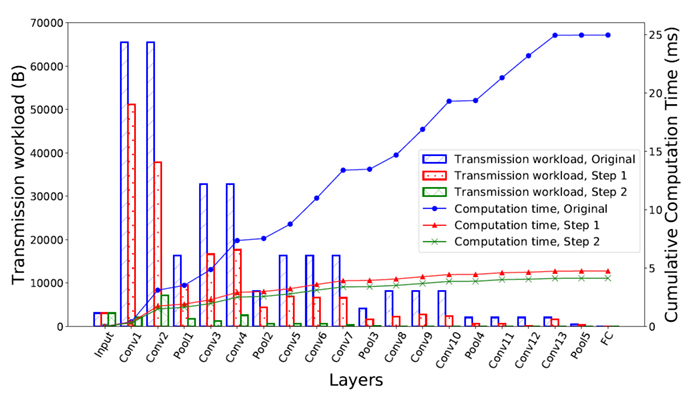
Figure 3: Layer level transmission and computation characteristics of the original, step 1 pruned and step 2 pruned VGG.
Table 1 shows the end-to-end latency improvements for three typical mobile networks (3G, 4G and WiFi) with computation capability ratio selected as 5. By applying our 2-step-pruning framework, a 4.8× acceleration can be achieved in WiFi environments.
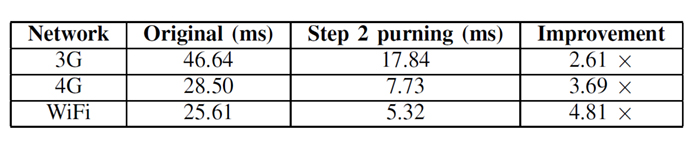
Table 1: End-to-end latency improvement under 3 typical mobile networks with selected computation capability ratio.
Based on above analysis and simulation, we are recommending the 2-step pruning framework through which the users could balance their preference between computation workload and transmission workload.
For more details, we encourage you to read our paper, “Improving Device-Edge Cooperative Inference of Deep Learning via 2-Step Pruning”, which can be accessed at https://arxiv.org/abs/1903.03472v1.
Thanks to my co-authors Wenqi Shi, Yunzhong Hou, Sheng Zhou, Zhisheng Niu from Tsinghua University, with whom this research work was jointly executed.